Low-supervision visual learning through cooperative agents
Summary
We do not have explicit labels for most of the data available to us. However, we observe that we can create auxillary tasks so that solving them creates unsupervised representations that can be useful as pretexts for other tasks.
In this work, we propose an auxillary task which does not need any explicit labels. We ask a system of two agents to find an image from a collection of images by playing a partial information cooperative game.
More concretely, let us say there are two agents A and B. A has a collection of images, while B has one image from that collection. A does not know which image B has, and the task for A is to correctly guess the image B has. For this, A can ask questions and B can answer them. This is a cooperative game because B’s task is to help A.
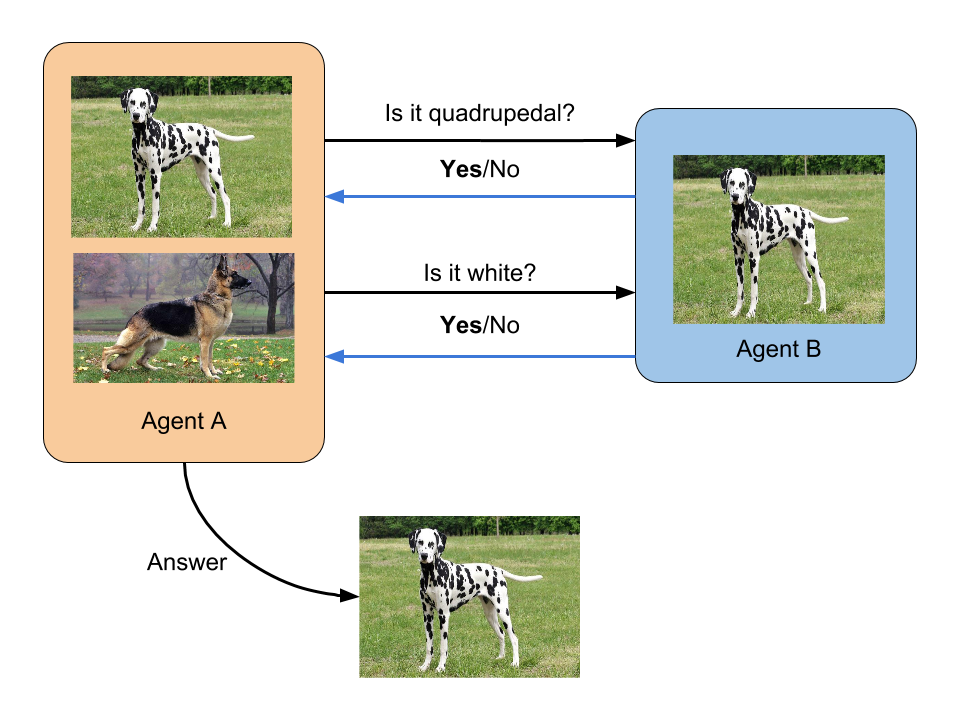
In absence of any restriction on the communication between A and B, the agents can conspire by developing some shared hash of the image and B can just tell the answer to A using that. Thus, we restrict the communication channel between the agents. We hypothesize that we can usefully restrict the communication type and direction to force these agents to learn visual cues.
In this work, we present an attempt at proof of concept of this idea using image attribute prediction based questions. We model each agent as using Convolutonal Neural Networks and present various training strategies for this setting. Please see the report and code (link at the top) for more details.